Cet article n’a PAS été rédigé par ChatGPT. Les différentes sources de l’article sont référencées en notes de bas de page.
ChatGPT est un prototype d’agent conversationnel basé sur le modèle de langage GPT développé par OpenAI, une société cofondée en 2015 par Elon Musk et Sam Altman et spécialisée dans le développement de l’intelligence artificielle. L’intelligence artificielle représente tout outil utilisé par une machine afin de « reproduire des comportements liés aux humains, tels que le raisonnement, la planification et la créativité». ChatGPT « est affiné en continu grâce à l’utilisation de techniques d’apprentissage supervisé et d’apprentissage par renforcement (« deep learning »), afin d’améliorer les performances du logiciel.»
Le nom « ChatGPT » vient de la combinaison des termes « chat » et « GPT », qui signifient respectivement « conversation » + « Generative Pre-trained Transformer ». Cela reflète la capacité du « chatbot » (robot conversationnel) à générer et simuler des conversations humaines.
ChatGPT est ainsi capable de répondre à des questions dans un langage proche de celui d’un humain, et ce dans de nombreuses langues. ChatGPT peut traduire des textes, écrire un texte (poème, article, roman…) sur un thème donné, donner des informations sur l’actualité ou résumer des concepts complexes (scientifiques, philosophiques…), générer des lignes de code, etc.
L’accès à ChatGPT est libre, mais nécessite d’ouvrir un compte sur le site Web d’OpenAI. Les demandes des utilisateurs et les réponses contribuent à l’apprentissage du robot (« deep learning[1] »).
Développement fulgurant de l’IA VS. Encadrement légal et règlementaire : 1 – 0
Microsoft a annoncé investir plusieurs milliards de dollars dans ChatGPT, a testé son intégration à son moteur de recherche Bing et a annoncé vouloir l’intégrer dans ses outils en ligne comme Word, Outlook ou Powerpoint…
Qu’à cela ne tienne, mi-mars a vu le lancement d’une IA concurrente « Claude », l’implémentation par Google de son propre agent conversationnel dans sa suite logicielle bureautique G-Suite, et la sortie d’une nouvelle version de ChatGPT, GPT-4 qui permet notamment d’intégrer des images dans les requêtes. Meta et Baidu sont également dans la course… L’IA peut être utilisée dans pléthore de domaines : la recherche en ligne, la traduction automatique, la publicité et le profilage en ligne, les assistants personnels (tels que Siri ou Alexa), les transports, la santé, les objets connectés, l’administration publique, etc.
D’un autre côté, cette course effrénée ne doit pas faire oublier les limites de ces outils « intelligents » qui peuvent générer des erreurs ou des biais, voire enfreindre la loi ou règlementation.
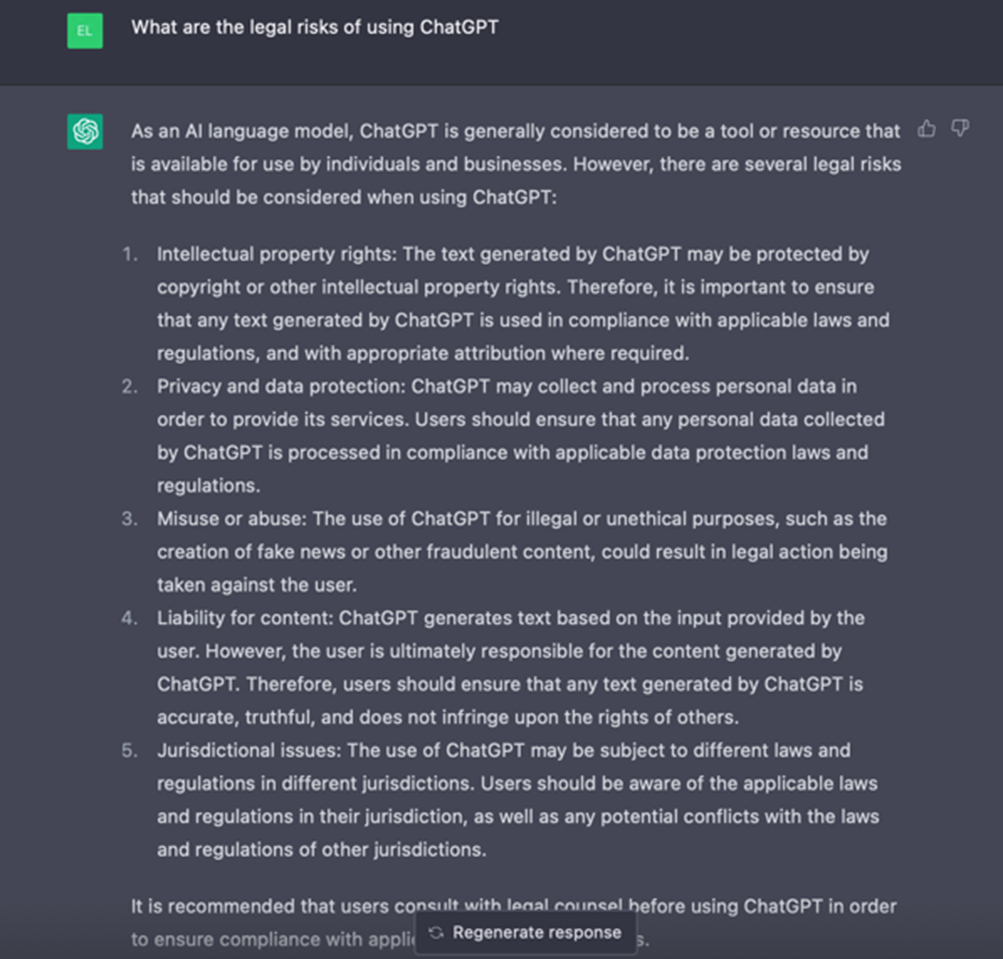
ChatGPT peut tout d’abord être source de discrimination, d’injustice selon les données sur lesquelles il se base pour apporter des réponses.
ChatGPT peut aussi être source de violation de droits de propriété intellectuelle, puisque l’outil se base sur une grande variété de contenus accessibles ainsi que sur les apports des utilisateurs de l’outil. Il peut entraîner une violation de la confidentialité ou des données à caractère personnel si des données confidentielles ou personnelles sont présentes dans les données extraites par ChatGPT pour répondre aux demandes de ses utilisateurs.
ChatGPT peut aussi créer des fausses informations ou du contenu à des fins frauduleuses (comme du code malveillant). Récemment, de fausses images générées par des IA ont circulé sur les réseaux sociaux et renforcent polémique et confusion.
A ce jour, aucun texte n’encadre encore le développement de l’intelligence artificielle. Une proposition de règlement européen sur l’intelligence artificielle est en cours d’élaboration et vise à encadrer les usages des systèmes d’intelligence artificielle. La CNIL a adopté un avis sur la proposition en juillet 2021 et s’est positionnée pour assumer le rôle d’autorité de contrôle en charge de l’application du règlement en France.
Le Règlement général sur la protection des données (RGPD) en application depuis le 25 mai 2018 prévoit de son côté que toute personne puisse s’opposer à des traitements automatisés engendrant une décision ayant un effet juridique à son égard (demande de prêt par exemple) lorsque ceux-ci n’intègrent pas une intervention humaine dans le processus de décision (En 2017, la CNIL avait initié une réflexion sur les dangers de l’IA afin de bâtir une éthique des algorithmes).
Enfin, la proposition de règlement ePrivacy toujours en cours de discussion mais aussi le Digital Markets Act (DMA), le Digital Services Act (DSA), et le Data Governance Act (DGA), prochainement applicables[2], pourront avoir des conséquences importantes pour les acteurs de l’intelligence artificielle qui proposeront des services de communication électroniques ou a contrario pour les plateformes de services de communication électroniques qui utilisent des algorithmes de recommandation.
L’IA va-t-elle remplacer l’humain ?
Rappelons que le terme anglais « intelligence » peut faire davantage référence au « renseignement » qu’à l’intelligence au sens « smartness », « understanding ». Ce qui éclairerait l’ « artificial intelligence » (AI) d’un autre sens : un outil de renseignement au service de l’humain. C’est ce à quoi appellent de leurs vœux de nombreux acteurs, pour accompagner un usage vertueux de l’outil, en faire un atout plutôt que le diaboliser. L’étude publiée par le Conseil d’État en 2022 va dans ce sens, en plaidant pour une politique volontariste de déploiement de l’intelligence artificielle, au service de l’intérêt général et de la performance publique (Respectivement en mai 2023 et en septembre 2023 pour le DMA et DGA et en février 2024 pour le DSA (2023 pour les très grandes plateformes/moteurs de recherche).
Appel public du cofondateur d’OpenAI à mettre en pause la course effrénée à l’IA
Plus de 50 000 personnes, dont Elon Musk, PDG de Tesla et cofondateur d’OpenAI, et Steve Wozniak, cofondateur d’Apple, ont co-signé une lettre ouverte dans laquelle ils demandent aux gouvernements d’ordonner pendant au moins six mois la suspension des recherches visant à créer des systèmes encore plus puissants que GPT-4 ; et ce afin de pallier pendant ce laps de temps l’absence d’encadrement éthique et règlementaire, l’avancée extrêmement rapide de la technologie étant perçue comme une menace pour l’humanité. Si le but affiché est honorable, six mois, est-ce suffisant pour encadrer, légiférer ?
Alors, véritable prise de conscience des dangers de la course effrénée à l’intelligence artificielle ou volonté de distancer les concurrents ? Affaire à suivre.
[1] Le « deep learning » ou apprentissage profond est un type d’intelligence artificielle dérivé du machine learning (apprentissage automatique) où la machine est capable d’apprendre par elle-même, à partir de données de départ. Ensuite, plus la machine accumule d’expériences différentes, plus elle sera performante.
[2] Respectivement en mai 2023 et en septembre 2023 pour le DMA et DGA et en février 2024 pour le DSA (2023 pour les très grandes plateformes/moteurs de recherche).